この記事は Mapbox Advent Calendar 2022 の12日目の記事です。
Mapbox の弱点として、3D のデータ表現が弱いということが言われます。確かに、3D 地図の上空に何かを配置したり、3D の点群を地図に重ね合わせて表示するための標準的な機能はありません。もちろん、カスタムスタイルレイヤーを使って、直接 WebGL もしくは Three.js のようなライブラリで 3D オブジェクトを配置することもできますが、あまり手軽ではありません。あるいは fill-extrusion レイヤーの fill-extrusion-base プロパティを使って、宙に浮いた押し出しポリゴンの物体を表示するという方法もありますが、何となく無理やり感が拭いきれません。
そこで便利な方法が、Mapbox GL JS と deck.gl の組み合わせです。deck.gl の GeoJsonLayer は Mapbox とは異なり、GeoJSON の高さパラメータ(GeoJSON 仕様 RFC 7946 ではオプショナル)をちゃんと解釈して 3D 空間に GeoJSON の要素を配置してくれるため、データを用意するだけで表示できるので手軽です。また、LineLayer、PathLayer、ScatterplotLayer、SolidPolygonLayer を使ってプリミティブな要素を表示することもできますし、地点間の繋がりを 3D の弧で表現できる ArcLayer や、loaders.gl でロードした 3D オブジェクトや luma.gl の 3D オブジェクトを表示する SimpleMeshLayer など、表現力の高いレイヤーを利用することもできます。
deck.gl の各レイヤーを Mapbox に組み込むには主に3つの方法があります(オーバーレイ、インターリーブの違いはこちらのページの図がわかりやすいです)。
1. MapboxOverlay を使ったオーバーレイ
Mapbox のレイヤーは1つの Canvas に、deck.gl のレイヤーは別の Canvas に描画し、最後に重ね合わせます。2D マップに適しています。
2. MapboxOverlay を使ったインターリーブ
Mapbox の各レイヤーと deck.gl の各レイヤーを共通の WebGL コンテキストで描画します。deck.gl のレイヤーはまとめて Mapbox のコントロールとして追加します。3D マップに適しています。
3. MapboxLayer を使ったインターリーブ
Mapbox の各レイヤーと deck.gl の各レイヤーを共通の WebGL コンテキストで描画します。deck.gl の各レイヤーは個別に Mapbox のカスタムスタイルレイヤーとして追加します。3D マップに適しています。
おすすめは「2. MapboxOverlay を使ったインターリーブ」です。共通の WebGL コンテキストを使って各レイヤーを描画するため、レイヤーをまたがって 3D オブジェクトの深度テストが行われ、物体の前後関係がきちんと反映されます。また、オブジェクトピッキング(マウス座標のオブジェクトの特定)にも対応します。
次のコードは、deck.gl の ScatterplotLayer を MapboxOverlay を使って Mapbox にインターリーブする例です。
import {Map} from 'mapbox-gl';
import {MapboxOverlay} from '@deck.gl/mapbox';
import {ScatterplotLayer} from '@deck.gl/layers';
const map = new Map({
center: [139.7670, 35.6814],
zoom: 14,
pitch: 60
});
const overlay = new MapboxOverlay({
interleaved: true,
layers: [
new ScatterplotLayer({
id: 'my-scatterplot',
data: [
{position: [139.7670, 35.6814, 1000], size: 100}
],
getPosition: d => d.position,
getRadius: d => d.size,
getFillColor: [255, 0, 0],
beforeId: 'admin_labels' // この Mapbox レイヤー ID の直下に挿入する
})
]
});
map.addControl(overlay);
地下に物体を配置した時の問題
さて、これで一件落着というところですが、このままでは地下に物体を配置した時に問題が起きる場合があります。具体的には、ズームレベルを変えたり、ピッチを変えたりしたときに地下のオブジェクトが欠けたり見えなくなることがあります。これはいったい何でしょう?
通常 3D 表示を行うアプリケーションは、描画パフォーマンス最適化のために、カメラを向けた空間を視錐台(Viewing frustum)と呼ばれる領域に区切り、その内部にある物体のみを描画します。Mapbox や deck.gl も例に漏れずこれに従っていますが、地表面にあるものの表示に最適化しているためか、基本的に地下の領域は見えないものとして扱っているフシがあります。
次の図は、視錐台を横から見た様子です。実装のコードを見てみると、視錐台の後方クリップ面は視野内の地表全体が見えるぎりぎりのところまで視点寄りになるように計算されています。視点から後方クリップ面までの距離(farZ)は、視野内の地表の最も遠い距離(furthestDistance)と、視界が届くものと仮定する距離(horizonDistance)のいずれか小さい方になります。そして horizonDistance は、カメラから地表までの距離(cameraToSeaLevelDistance)の10倍という固定値になっています。

真上から見た場合、furthestDistance は地表までの距離と同じになるため、地下の物体はまったく表示されません。水平線が見えない程度のピッチの場合、furthestDistance は画面上端に当たる部分の地表までの距離になりますが、この場合見える物体と見えない物体が出ますし、地下深くのものはいずれにしろ見えないでしょう。さらに、画面に水平線が見えている場合は、furthestDistance は無限大(実際にはクリップされて非常に大きい値)になりますので horizonDistance が支配的になりますが、cameraToSeaLevelDistance の10倍より遠くの物体は表示されなくなるため、特にズームインした時の地下の見える範囲が狭まります。
ビューポートの farZ パラメータを調整する
対策はどのようになるでしょうか。直感的に思いつくのは、地下の物体が見えるように後方クリップ面を大きく後方にずらすことです。しかし、これの弊害は、表示する 3D オブジェクトの数が増える可能性があり、最悪の場合描画パフォーマンスが大幅に落ちること、そして、深度テストを行う際の計算誤差が出やすくなり、ポリゴンのちらつき(z-fighting)が起こる可能性が増えることです。このため、ずらすにしてもできる限り影響の少ない量にする必要があります。
例えば、地下1kmまでの何らかの分布データを表示することを想定しましょう。まず、furthestDistance による判定は、不要なので考慮から外します。そして新たな farZ の値は、horizonDistance か、(cameraToSeaLevelDistance + 1km) のいずれか大きい方、とすればおおよそ良いのではないかと思います。
では、視錐台を決定するビューポートの farZ の設定はどこで行なっているでしょうか。Mapbox では src/geo/projection/far_z.js の 26行目、
return Math.min(furthestDistance * 1.01, horizonDistance);
というところを
return Math.max(horizonDistance, cameraToSeaLevelDistance + (1000m));
のように変えてやれば良いはずです。しかし注意が必要です。ここでの距離の単位はメートルではなく「スクリーンピクセル」です。メートルをスクリーンピクセルに単位変換するには、tr.pixelsPerMeter を掛けてやれば良さそうです。
return Math.max(horizonDistance, cameraToSeaLevelDistance + 1000 * tr.pixelsPerMeter);
一方、deck.gl は math.gl の modules/web-mercator/src/web-mercator-utils.ts の 334行目、
const farZ = Math.min(furthestDistance * farZMultiplier, horizonDistance);
というところを
const farZ = Math.max(horizonDistance, cameraToSeaLevelDistance + (1000m));
と変えれば良さそうです。こちらは単位は「スクリーン(スクリーンの高さを1とする)」です。しかし、math.gl には単位変換するための係数がないため、このコードが含まれる getProjectionParameters を呼び出している deck.gl の modules/core/src/viewports/web-mercator-viewport.ts の 157-167行目に次の赤字の行の unitsPerMeter というパラメータを加えてやります。
projectionParameters = getProjectionParameters({
width,
height,
scale,
center: position && [0, 0, position[2] * unitsPerMeter(latitude)],
offset,
pitch,
fovy,
nearZMultiplier,
farZMultiplier,
unitsPerMeter: scale * unitsPerMeter(latitude) / height
});
そして math.gl の modules/web-mercator/src/web-mercator-utils.ts の 276-298行目でその unitsPerMeter を受け取ってやり、
export function getProjectionParameters(options: {
width: number;
height: number;
scale?: number;
center?: number[];
offset?: [number, number];
fovy?: number;
altitude?: number;
pitch?: number;
nearZMultiplier?: number;
farZMultiplier?: number;
unitsPerMeter:? number;
}): ProjectionParameters {
const {
width,
height,
altitude,
pitch = 0,
offset,
center,
scale,
nearZMultiplier = 1,
farZMultiplier = 1,
unitsPerMeter
} = options;
先ほどの334行目を次のように変えてやります。
const farZ = Math.max(horizonDistance, cameraToSeaLevelDistance + 1000 * unitsPerMeter);
最後に
さて、以上の通り、地下に物体を配置するために Mapbox GL JS、deck.gl の両方のコード本体に手を入れるというハッキングを行いました。ビューポートはそれぞれで設定しているのですが、結果は正確に一致していないと深度テストの結果が正しくなくなり表示がおかしくなるので解明に苦労しました。描画パフォーマンスとのトレードオフなので、本体にコントリビュートするというのはちょっとないかな、と思っています。
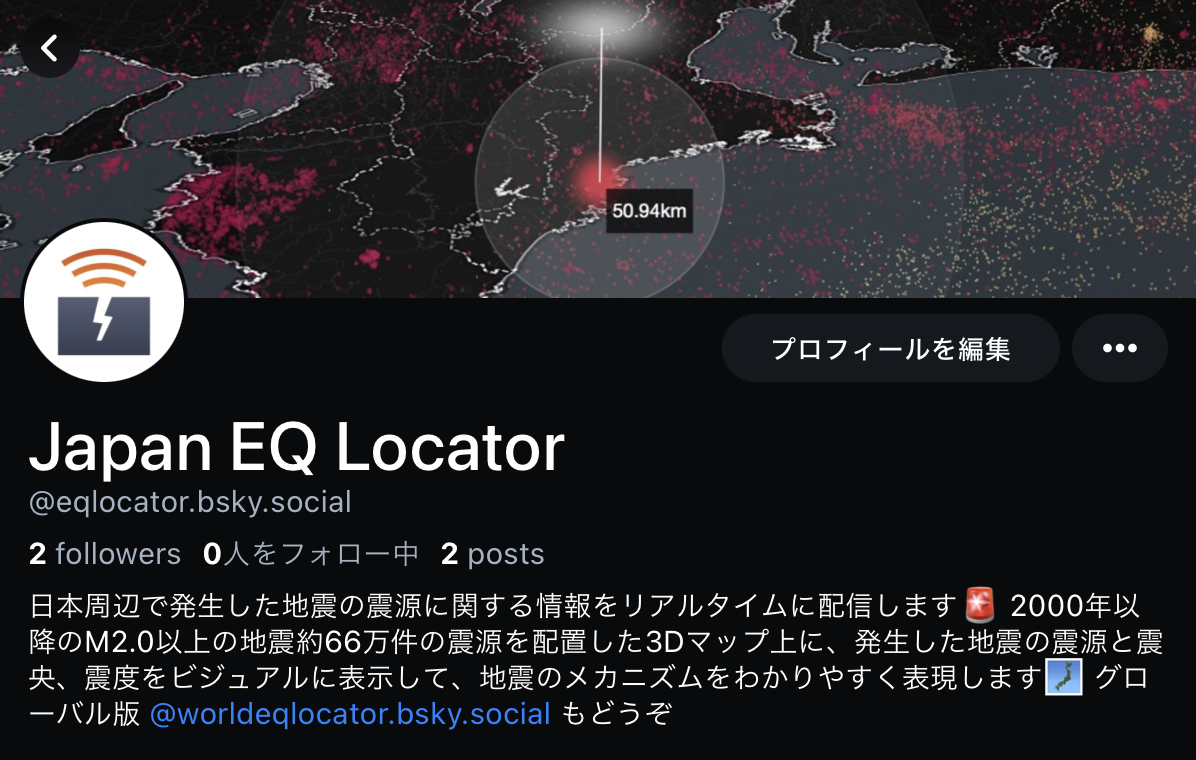
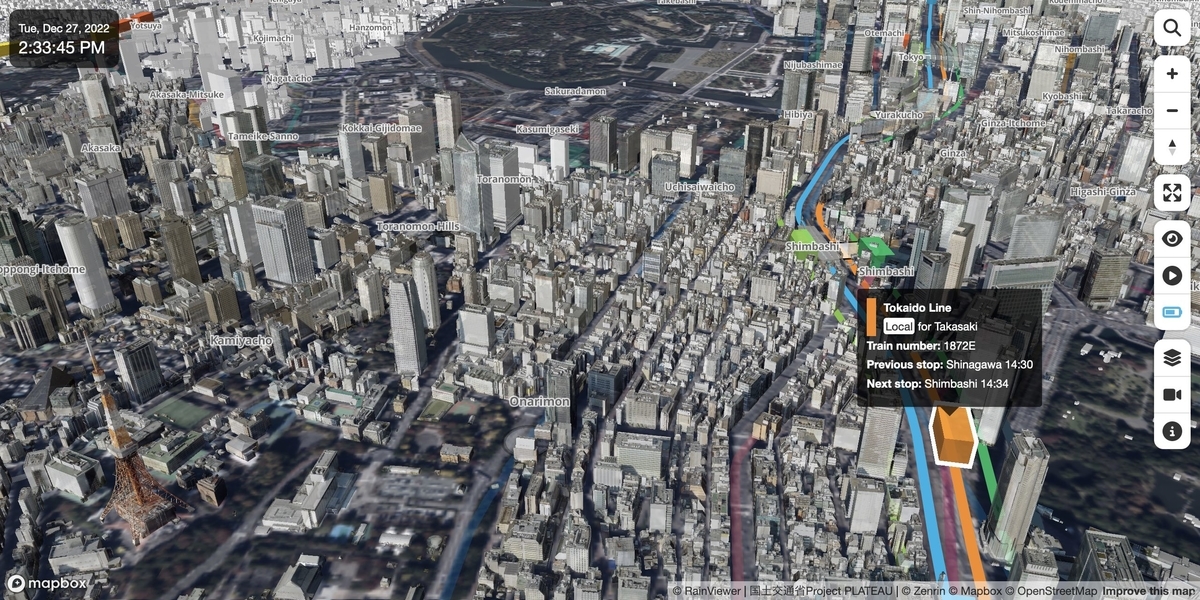
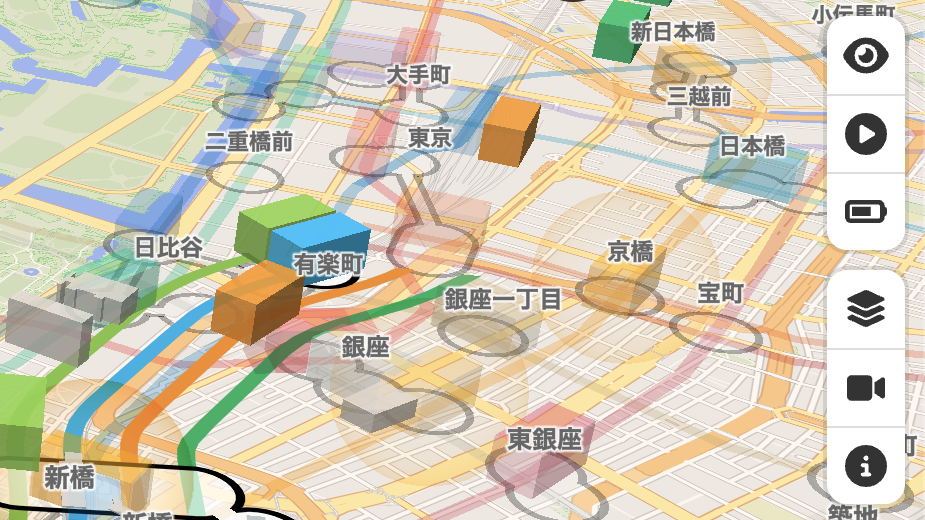
この手法は、Mini Tokyo 3D の地下鉄路線や列車の表示、そして Japan EQ Locator の地下の震源の表示でも使われています。